JPA 的封装和使用
一切一切为了简化操作,远离 CRUD,提升开发体验
核心操作
JPA 的封装在 developer-sql-jpa 中,基本上将数据库的核心关键词都已经封装
在 application.yml 中定义了 JPA 的分割符
# version: 2.0
baseSqlQuery:
opSeparator: _ #主要用于分割字段与操作符
例如:
- name_Like,转换为 SQL 为
name like '%?%' - name_StartWith,转换为 SQL 为
name like '?%' - createdAt_Gt,转换为 SQL 为
created_at > ?...
操作符说明
如果一个字段不带关键词,那么就是 equal
| 操作符 | 说明 | 备注 |
|---|---|---|
| Is | equal | 一般不需要使用,默认就是 equal |
| Eq | equal | 一般不需要使用,默认就是 equal |
| Neq | notEqual | 不等于 |
| StartWith | like(root.get(queryField), val + "%") | 首字符匹配 |
| EndWith | like(root.get(queryField), "%" + val) | 尾字符匹配 |
| Like | like(root.get(queryField), "%" + val + "%") | 相似匹配 |
| Gt | greaterThan | 大于 |
| Gte | greaterThanOrEqualTo | 大于等于 |
| Lt | lessThan | 小于 |
| Lte | lessThanOrEqualTo | 小于等于 |
| NotNull | isNotNull | 非 null,3.0.4 版本进行了优化,value 可以输入 null |
| Null | 为 null | isNull ,同样在 3.0.4 版本中进行了优化,value 可以输入 null |
| Between | between | 在 x,x 之间 |
| In | in | 在数组内 |
| NotIn | not in | 不在数组内 |
| FindInSet | MySql 的 find_in_set 方法 | 3.0.7 升级上线,特别适合存储 ids 的查找场景FindInSet |
如果你希望的操作符不在上面关键词中,那么可以向 TerryQi 提出改进
- 2022 年 10 月 22 日
在 orderBy 中提供获取随机数的方法,提供 rand()的关键词,可以乱序获取列表数据,具体用法如下:
BaseSqlQuery baseSqlQuery = (BaseSqlQuery) query;
baseSqlQuery.orderBy("rand()", null);
当然,这个能力已经在 Manager 层进行封装,具体方法为 randomOne 和 randomList
指定条件排序
在某些场景下,需要根据指定字段进行排序,即在 Qo 中,需要指定根据某些字段来升序或者降序,3.1.1 版本中,针对 BaseQuery 进行了升级,可以指定
LinkedHashMap<String, Sort.Direction> orderBy字段,完成排序操作
基础用法
首先,我们扩展了 BaseQuery 能力,可以多传入一个参数LinkedHashMap<String, Sort.Direction> orderBy,这个参数就代表排序规则,LinkedHashMap 代表一个有序的 Map(因为排序规则是有序的);String代表字段;orderBy代表升序或者降序
!!!请注意,在 Qo 中,排序字段值必须叫做orderByCustomSort,否则就要在创建 BaseQuery 中,指定排除的字段
@Data
public class SysNationCodeQueryQo extends PageableQo {
@ApiModelProperty(value = "民族名称", example = "", required = false)
private String name_Like;
@ApiModelProperty(value = "民族编号", example = "", required = false)
private String code;
@ApiModelProperty(value = "根据指定条件排序", example = "", required = false)
private LinkedHashMap<String, Sort.Direction> orderByCustomSort;
}
目前,默认 qo 中定义排序的字段为orderByCustomSort,当然你也可以自定义字段,那么就需要在创建 BaseQuery 时,指定这个字段不要进入 Where 的条件
// 这里第二个参数就是个性化排序的Map
Specification query = new BaseSqlQuery(qo, qo.getOrderByCustomSort());
nationCodeManager.findAll(query);
如果自己定义为 myOrderBy,那么要注意增加fieldExclude字段,这个字段的含义是不加入 Qo 的 where 排序条件中
// 这里第二个参数就是个性化排序的Map,例如自己可以定义为myOrderBy
Specification query = new BaseSqlQuery(qo, qo.getMyOrderBy(),{"myOrderBy"});
nationCodeManager.findAll(query);
orderBy 的个性化处理
2024 年 5 月,为了解决根据检索结果排序的问题(例如 TopN 用户访问量等),增强了 orderBy 的属性,在 orderBy 中,可以根据字段结果进行排序
| 操作符 | 说明 | 备注 |
|---|---|---|
| Count | 进行统计 | 翻译出来的 Sql 就是 count(--) |
| CountDistinct | 去重统计 | 翻译出来的 Sql 就是 count(distinct --) |
| Sum | 求和 | 翻译出来的 Sql 就是 sum(--) |
| Max | 求和 | 翻译出来的 Sql 就是 max(--) |
| Min | 求和 | 翻译出来的 Sql 就是 min(--) |
| Avg | 求和 | 翻译出来的 Sql 就是 avg(--) |
| DateFormat | 转换为日期格式,即年-月-日 | 翻译出来的 Sql 就是 date_format(field,'%Y-%m-%d') |
| MonthFormat | 转换为日期格式,即年-月 | 翻译出来的 Sql 就是 date_format(field,'%Y-%m') |
| HourFormat | 转换为小时格式,即时(24 小时制) | 翻译出来的 Sql 就是 date_format(field,'%H') |
SmartSqlQuery query = (SmartSqlQuery) new SmartSqlQuery()
.multiSelect(Arrays.asList("provinceCityId_Count@num", "cityLevel"))
.groupBy("cityLevel")
.orderBy("provinceCityId_Count", Sort.Direction.ASC)
.setLimit(2).setOffset(1);
List<ProvinceDo> doList = provinceCityManager.smartFind(query, ProvinceDo.class);
上述例子中,就可以根据 provinceCityId_Count 的结果进行排序了,有问题请 call TerryQi
关于 limit 和 offset 关键词
通过 limit 和 offset,可以进行数据条目和偏移量的控制,和 MySQL 中的 limit、offset 的概念一样
在 BaseSqlQuery 和 SmartQuery 中,都提供了 limit、offset 属性,特别适合于获取 TopN 数据的需求
BaseSqlQuery query = (BaseSqlQuery) new BaseSqlQuery()
.setLimit(2).setOffset(1).setDataScope(DataScopeEnum.ALL);
List<SysProvinceCityEntity> doList = provinceCityManager.findAll(query);
Assert.assertTrue(true);
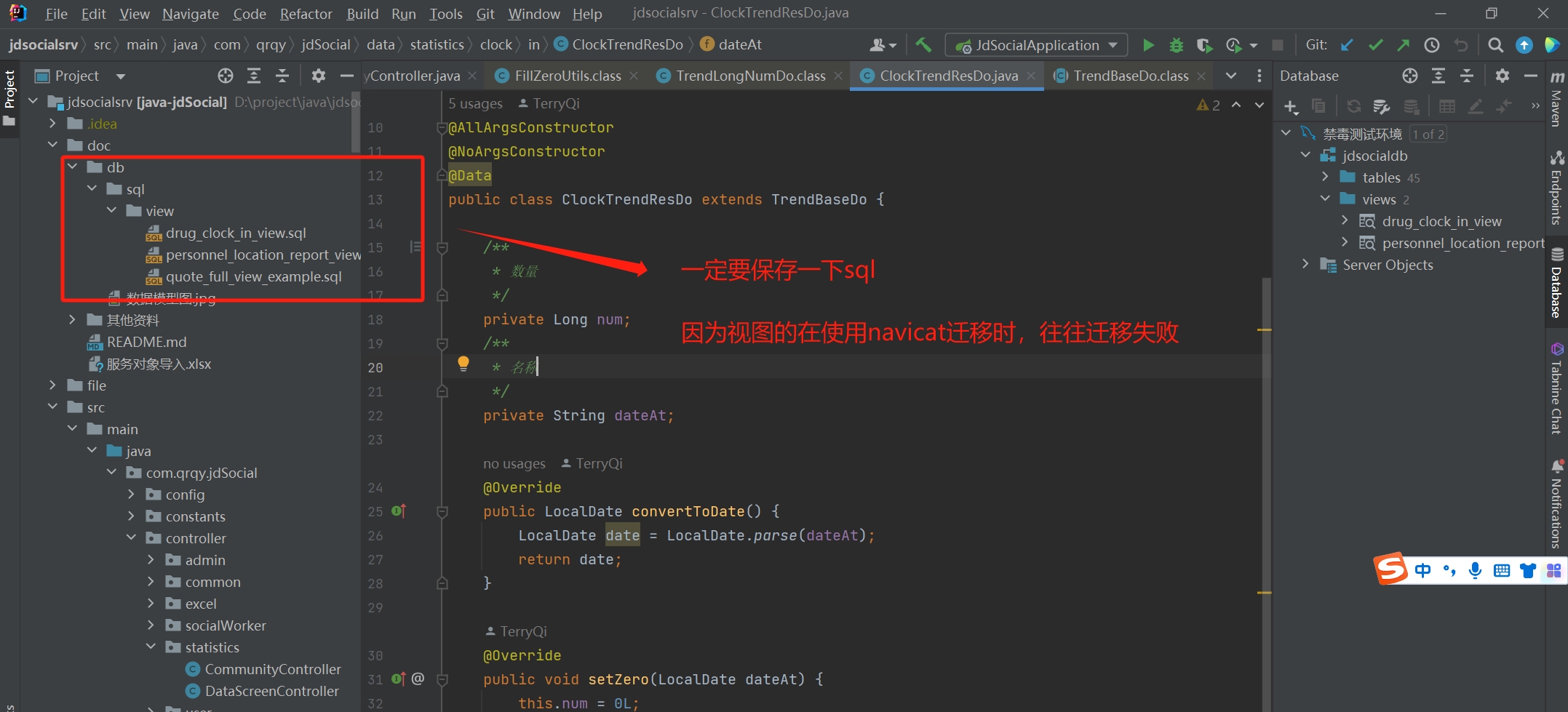
view 视图的使用(重要)
在实施 XX 项目时,发现我们的开发人员在 repository 中写了比较复杂的原始 sql 语句,究其原因,是因为项目中使用到了跨表的关联查询,由于 JPA 对跨表关联查询并不友好,导致我们的代码既复杂、又难懂,还有很多的语法级别的问题
JPA、Mybatis-plus 都不能很好地做跨表的复杂关联查询,但是我们 JPA 的单表查询能力很强,怎么办?
答案是 视图操作,使用视图会很好地解决复杂查询的问题,将跨表关联转查询换为单表查询,那么视图的缺点也很明显:
视图不好维护,在使用 navicat 进行数据迁移时,视图往往迁移不完整,所以要在代码中保存一下视图。位置在/doc/sql/view 目录中,一个视图一个 sql
表调整视图也需要同步调整,这里也不算是缺点,因为原始表调整的话,无论 Entity 还是我们的原始 sql 都需要调整
!!! 请注意,大家要理解视图的概念,视图仅仅用来查询,是无法用来增、删、改数据的。
视图的创建
正常的建设视图的语句,本质就是 sql 语句,那么请注意,视图一定要以 xxx_view 来命名,那么我们就知道 xxxViewEntity 是视图了
例如下面视图语句,就是将打卡记录补充执行区域信息
/**
主要补充打开信息的execute_area_id字段
*/
CREATE VIEW drug_clock_in_view AS
(
SELECT dci.*,
dp.execute_area_id AS execute_area_id
FROM drug_clock_in AS dci
LEFT JOIN drug_personnel AS dp ON dci.drug_personnel_id = dp.drug_personnel_id
)
视图的使用
与表一样生成 Entity 和 Manager 使用,要注意保存好视图的 sql(以便于在生产环境创建),接下来可以愉快地使用视图啦
对于一些联合查询、趋势统计很有效率,而且代码清晰、条件易于拼装,会很大的提升我们的开发体验
SmartQuery
历史上,数据趋势统计等能力都需要自定义 Sql 的方式来编写,不是很友好。其实 Jpa 给出的灵活 Sql 的能力与 laravel 的 ORM 几乎是一样的,那么通过 SmartQuery 的封装,对于单表可以进行比较灵活的统计类操作,也就是 count 和 groupBy
说明
SmartQuery 本质上是继承于 BaseSqlQuery,但是将 singleSelect, multiSelect 封装出来,在 multiSelect 中,可以加入所需要选择的列,并且附加操作符,可以加入的操作符如下
| 操作符 | 说明 | 备注 |
|---|---|---|
| Count | 进行统计 | 翻译出来的 Sql 就是 count(--) |
| CountDistinct | 去重统计 | 翻译出来的 Sql 就是 count(distinct --) |
| Sum | 求和 | 翻译出来的 Sql 就是 sum(--) |
| Max | 求和 | 翻译出来的 Sql 就是 max(--) |
| Min | 求和 | 翻译出来的 Sql 就是 min(--) |
| Avg | 求和 | 翻译出来的 Sql 就是 avg(--) |
| DateFormat | 转换为日期格式,即年-月-日 | 翻译出来的 Sql 就是 date_format(field,'%Y-%m-%d') |
| YearFormat | 转换为日期格式,即年 | 翻译出来的 Sql 就是 date_format(field,'%Y') |
| MonthFormat | 转换为日期格式,即年-月 | 翻译出来的 Sql 就是 date_format(field,'%Y-%m') |
| HourFormat | 转换为日期格式,即小时 | 翻译出来的 Sql 就是 date_format(field,'%H') |
| WeekFormat | 转换为日期格式,即周 | 翻译出来的 Sql 就是 date_format(field,'%u') |
| IOSWeekFormat | 转换为日期格式,即周 | 翻译出来的 Sql 就是 yearweek(field,1) |
Select 字段设置别名
一般情况下,尤其是统计数据,select 的值我们需要换个名字,那么可以@符号来设定别名,例如下面语句,就是count(code) as num,统计 code 值作为 num
selectFieldList.add("code_Count@num");
Count & Find
在 Manager 中提供了 SmartCount 和 SmartFind 方法,其中 SmartCount 是用于统计数据的功能,输出是一个值,例如统计每日的 Pv 数;SmartFind 是输出趋势图的功能,结合 GroupBy 可以输出 List 的数据
Count 的例子
例如综合统计平台,我们需要统计每日的 Uv 数,那么 Uv 是需要根据用户 id 进行去重处理的,则在 userUuid 后加 _CountDistinct 即可
那么 _下划线 之后就是跟随的操作
SmartSqlQuery query = (SmartSqlQuery<SysNationCodeEntity>)
new SmartSqlQuery<SysNationCodeEntity>().singleSelect("value_Max")
.append("status", CommonConst.COMMON_VALID);
BigDecimal value = (BigDecimal) nationCodeManager.smartCount(query);
翻译的 Sql 为
SELECT
count( DISTINCT tjsviewrec0_.user_uuid ) AS col_0_0_
FROM
tjs_view_record tjsviewrec0_
WHERE
tjsviewrec0_.deleted_flag = '0'
- 请注意,smartCount 不算很优雅,因为统一返回的值是 Number 类型,那么要根据具体的情况强制转换下,报错的时候有提示。例如 count 返回 Long、Avg 返回 Double、Sum 就遵循字段类型,如果是 BigDecimal,就要用 BigDecimal 来接收,我没有找到更优雅的方案,目前是这样(主要原因在于 JPA 不同操作的返回值不同)
结合 GroupBy 进行趋势统计
结合 GroupBy 进行趋势统计可能是最关键的功能啦,例如你需要统计每天的 Pv 和 Uv 趋势,那么定义好 Dto 后,通过 SmartQuery 就可以获取数据了
我们的综合统计平台就是通过 GroupBy 来实施的,例如下面 :
- Pv 统计的样例
List<String> multiSelect = Arrays.asList("userUuid_Count", "dateAt");
List<TrendLongNumDo> doList = viewRecordManager
.smartFind((SmartSqlQuery<TjsViewRecordEntity>) new SmartSqlQuery<TjsViewRecordEntity>(request)
.multiSelect(multiSelect).groupBy("dateAt"), TrendLongNumDo.class);
doList = FillZeroUtils.fillUpZero(doList, request.getDateAt_Gte(), request.getDateAt_Lte());
- Uv 统计样例
List<String> multiSelect = Arrays.asList("userUuid_CountDistinct", "dateAt");
List<TrendLongNumDo> doList = viewRecordManager
.smartFind((SmartSqlQuery<TjsViewRecordEntity>) new SmartSqlQuery<TjsViewRecordEntity>(request)
.multiSelect(multiSelect).groupBy("dateAt"), TrendLongNumDo.class);
doList = FillZeroUtils.fillUpZero(doList, request.getDateAt_Gte(), request.getDateAt_Lte());
- 分时 Pv 统计
List<String> multiSelect = Arrays.asList("userUuid_Count", "hourAt");
List<TimeDivideTrendDto> doList = viewRecordManager
.smartFind((SmartSqlQuery<TjsViewRecordEntity>) new SmartSqlQuery<TjsViewRecordEntity>(request)
.multiSelect(multiSelect).groupBy("hourAt"), TimeDivideTrendDto.class);
doList = TrendUtils.fillUpZero(doList);
为了支持前端业务,也提供了统一的补零工具,大家可以使用
趋势统计 HourFormat 处理
HourFormat 就是将数据库中的年-月-日 时:分:秒的数据转换为时(24小时制)的格式,这个场景是比较通用的,例如要根据日期中的小时统计某个趋势
怎么用?详见 SmartQuery 中的 HourFormat 信息
具体用法为:
SmartSqlQuery query = new SmartSqlQuery();
List<String> selectFieldList = new ArrayList<>();
selectFieldList.add("code_Count@num");
selectFieldList.add("code");
selectFieldList.add("createdAt_HourFormat@hourAt");
query.multiSelect(selectFieldList);
query.groupBy("createdAt_HourFormat");
List<NationTrendWithDateTimeDto> result = nationCodeManager.smartFind(query, NationTrendWithDateTimeDto.class);
请注意这里的 createdAt_HourFormat,就是代表在 createdAt 字段上,套 date_format( created_at, '%H' )函数
趋势统计 DateFormat 处理
顾明思议,DateFormat 就是将数据库中的年-月-日 时:分:秒的数据转换为年-月-日的格式,这个场景是比较通用的,例如要根据创建日期统计某个趋势,那么一般创建日期在数据库中是 createdAt 字段,是 datetime 类型的,所以要转换为 date 类型
怎么用?详见 SmartQuery 中的 DateFormat 信息
具体用法为:
SmartSqlQuery query = new SmartSqlQuery();
List<String> selectFieldList = new ArrayList<>();
selectFieldList.add("code_Count@num");
selectFieldList.add("code");
selectFieldList.add("createdAt_DateFormat@dateAt");
query.multiSelect(selectFieldList);
query.groupBy("createdAt_DateFormat");
List<NationTrendWithDateTimeDto> result = nationCodeManager.smartFind(query, NationTrendWithDateTimeDto.class);
请注意这里的 createdAt_DateFormat,就是代表在 createdAt 字段上,套 date_format( created_at, '%Y-%m-%d' )函数
- 解析 selectFieldList
下面语句的含义是将 createdAt 进行 DateFormat 化,并且起别名为 dateAt,一般在 select 的时候用到
selectFieldList.add("createdAt_DateFormat@dateAt");
- 解析 groupBy
下面语句的含义是将 createdAt 进行 DateFormat 化,并进行分组条件,因为很多的时间字段是 datetime 类型的,但是我们统计要使用 date 来统计
query.groupBy("createdAt_DateFormat");
上面的代码翻译为 sql 为
SELECT
count( sysnationc0_.CODE ) AS col_0_0_,
sysnationc0_.CODE AS col_1_0_,
date_format( sysnationc0_.created_at, '%Y-%m-%d' ) AS col_2_0_
FROM
sys_nation_code sysnationc0_
WHERE
sysnationc0_.deleted_flag = '0'
GROUP BY
date_format( sysnationc0_.created_at, '%Y-%m-%d' )
此外,请注意 NationTrendWithDateTimeDto,一般是和返回结果对应的,如果用了 DateFormat 方法,那么就要用 String 来接了,具体为:
@Data
@AllArgsConstructor
public class NationTrendWithDateTimeDto {
/**
* 数量
*/
private Long num;
/**
* 名称
*/
private String code;
/**
* 日期,请注意,是String类型
*/
private String dateAt;
}
趋势统计 MonthFormat 处理
在 3.1.9 版本中,提供了 MonthFormat 方法,具体用法与 DateFormat 类似,适合于根据月份进行统计的场景
提供了 FillZreoUtils 工具,用于补零,可以参考下 TrendMonthDo 的写法,要继承一个 MonthBaseDo 的抽象类,传入参数 MonthDurationDo 配合进行范围控制
List<String> selectFieldList = new ArrayList<>();
selectFieldList.add("code_Count@num");
selectFieldList.add("createdAt_MonthFormat@monthAt");
SmartSqlQuery smartSqlQuery = (SmartSqlQuery) new SmartSqlQuery().multiSelect(selectFieldList)
.groupBy("createdAt_MonthFormat");
List<TrendMonthDo> trendList = nationCodeManager.smartFind(smartSqlQuery, TrendMonthDo.class);
MonthDurationDo startMonthAt = new MonthDurationDo(2023, 1);
MonthDurationDo endMonthAt = new MonthDurationDo(2024, 6);
trendList = FillZeroUtils.fillUpZeroImpl(trendList, TrendMonthDo.class, startMonthAt, endMonthAt);
log.info("trendList:{}", trendList);
Assert.assertTrue(true);
翻译的 SQL 为
SELECT
count( sysnationc0_.CODE ) AS col_0_0_,
date_format( sysnationc0_.created_at, '%Y-%m' ) AS col_1_0_
FROM
sys_nation_code sysnationc0_
WHERE
sysnationc0_.deleted_flag = '0'
GROUP BY
date_format( sysnationc0_.created_at, '%Y-%m' )
增强补零工具
趋势图往往都要结合补零工具使用,例如分组查询 Pv 的趋势,那么数据库中的数据根据 createdAt 进行分组,可能数据是不连续的,那么如何进行补零呢?
TrendBaseDo 抽象类
TrendBaseDo 是一个趋势图基础的抽象类,提供两个方法:
- convertToDate 方法
即将你的趋势数据中的日期转换为 LocalDate 类型,因为可能日期是 String 类型的(例如用了上面的 DateFormat),所以你要实现一下这个方法,将其转换为 LLocalDate 类型
- setZero 方法
setZero 约等于是数据初始化,即如果搜索的数据中没有当前的日期,那么就需要补零,补零数据的初始化应该是什么样子的
@Data
public abstract class TrendBaseDo {
/**
* 返回日期信息,用于补零操作
*
* @return
*/
public abstract LocalDate convertToDate();
/**
* 初始化数据
*
* @return
*/
public abstract void setZero(LocalDate dateAt);
}
怎么用?
- 首先,定义你的趋势 Dto,实现 convertToDate 方法和 setZero 方法,可以看到,日期已经不非得叫 dateAt 了
@Data
@NoArgsConstructor
@AllArgsConstructor
public class NationTrendWithDateDto extends TrendBaseDo {
/**
* 数量
*/
private Long num;
/**
* 名称
*/
private String dateAt;
@Override
public LocalDate convertToDate() {
LocalDate date = LocalDate.parse(dateAt);
return date;
}
@Override
public void setZero(LocalDate dateAt) {
this.num = 0L;
this.dateAt = dateAt.toString();
}
}
- 使用增强补零工具进行补零操作
SmartSqlQuery query = new SmartSqlQuery();
List<String> selectFieldList = new ArrayList<>();
selectFieldList.add("code_Count@num");
selectFieldList.add("createdAt_DateFormat@dateAt");
query.multiSelect(selectFieldList);
query.groupBy("createdAt_DateFormat");
//用SmartFind获取的趋势数据
List<NationTrendWithDateDto> result = nationCodeManager
.smartFind(query, NationTrendWithDateDto.class);
log.info("result:{}", JSON.toJSONString(result));
//执行补零操作
List<NationTrendWithDateDto> fillUpDto = FillZeroUtils
.fillUpZeroImpl(result,NationTrendWithDateDto.class, LocalDate.now().minusDays(30),LocalDate.now());
log.info("fillUpDto:{}", JSON.toJSONString(fillUpDto));
以上可以实现各种 Dto 的补零,快、稳、便捷,也比较优雅
请注意,我们统一提供了 FillZerorUtils 的补零工具,在 3.1.2 版本中,进一步提供了 TrendNormalLongDo 的标准 Do 结构(包含 num 和 dateAt 字段),一般小型趋势图都可以使用,就不用自己定义 Do 了
关于 Entity
Entity 是通过 jDaoMySQL-v3.groovy 来生成的,具体详见 JDaoMySQL 的使用
请注意字段枚举值的设定,下面例子中 relTable 就是枚举值
PS:CommonEntity 默认的 Id 一定是 Integer 型的,3.0.5 版本进行了升级,提供了 Common2Entity,通过泛型管理 id、createdBy、updatedBy、deletedBy 等字段,具体详见JPA 审计
/**
* @author : jCoder
* @date : 2022-07-21 00:10
*/
@Data
@EqualsAndHashCode(callSuper = true)
@Entity
@Table(name = "sys_account_auth")
@EntityListeners(AuditingEntityListener.class)
public class SysAccountAuthEntity extends CommonEntity implements Serializable{
private static final long serialVersionUID = 427821568216479352L;
/**
* PK
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "account_auth_id")
private Integer accountAuthId;
/**
* 关联表名,一般情况下为SYS_USER,即关联sys_user表的用户数据,部分业务中,可能鉴权信息要对应例如sys_user、sys_admin两个表,那么rel_table就是需要关联的表
*/
@Column(name = "rel_table")
@Enumerated(EnumType.STRING)
private RelTableEnum relTable;
/**
* 关联表的id,一般为用户表的id
*/
@Column(name = "rel_id")
private Integer relId;
/**
* TOKEN
*/
@Column(name = "token")
private String token;
/**
* TOKEN有效期
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@Column(name = "valid_at")
private LocalDateTime validAt;
/**
* key,加密用
*/
@Column(name = "secret_key")
private String secretKey;
/**
* sercret,加密用
*/
@Column(name = "secret_value")
private String secretValue;
/**
* 状态,是否生效,0:未生效;1:生效
*/
@Column(name = "status")
private String status;
}
关于 Manager 和 Repository
请注意,我们的代码分层结构为 Controller->Service->Manager->Repository,其中:
- Service:一般会封装一些业务,例如带事务
- Manager:单表的业务,如果判断用户名是否重复,给 Service 使用
- Repository:单表的 CRUD
Manager 封装方法
Manager 方法都继承于 BaseSqlManager
| 方法 | 说明 | 备注 |
|---|---|---|
| findOne | 找到 1 条数据 | 返回 option,一般需要跟.orElse(null) |
| findById | 根据 id 获取数据 | 返回 option,一般需要跟.orElse(null) |
| findAll | 获取列表数据 | |
| count | 计数 | |
| save | 保存 | |
| saveAll | 批量保存 | |
| delete | 删除 | |
| deleteBatch | 批量删除 | |
| setSort | 设置顺序 | |
| setStatus | 设置状态 | |
| query | 同 findAll | |
| get | 根据 id 获取数据 | |
| randomOne | 随机 1 条数据 | 3.0.7 版本提供 |
| randomList | 随机列表数据 | 3.0.7 版本提供 |
| findFirstOne | 获取第一条数据 | 3.1.4 版本提供 |
| findTopNList | 获取头部几条数据 | 3.1.4 版本提供 |
| batchSaveAll | 批量保存数据(多线程) | 3.1.4 版本提供,需要持续验证 |
| SchemaManager | 执行原生 sql | 3.1.5 |
SchemaManager 的用法
执行项目的过程中,发现需要执行一些原生的 sql,以往都是在 repository 中实现,可能不够灵活,那么提供 SchemaManager 方法,完成 sql 的执行和对象映射
- 先定义映射的对象
@Data
@AllArgsConstructor
@NoArgsConstructor
public class TableDo {
/**
* 名称
*/
@ApiModelProperty(value = "表名", example = "")
private String tableName;
/**
* 备注
*/
@ApiModelProperty(value = "备注", example = "")
private String tableComment;
/**
* 库
*/
@ApiModelProperty(value = "库", example = "")
private String tableSchema;
/**
* 类型
*/
@ApiModelProperty(value = "类型", example = "")
private String tableType;
}
- 执行 sql 文件
String sql = "SELECT\n" +
"\tTABLE_NAME as tableName,\n" +
"\tTABLE_COMMENT as tableComment,\n" +
"\tTABLE_SCHEMA as tableSchema,\n" +
"\tTABLE_TYPE as tableType\n" +
"FROM\n" +
"\tinformation_schema.TABLES \n" +
"WHERE\n" +
"\ttable_type = 'BASE TABLE' \n" +
"\tAND table_schema = DATABASE ( );";
List<TableDo> results = schemaManager.nativeQuery(sql, TableDo.class);
Respository 封装方法
Respository 方法都继承于 IBaseSqlRepository,其功能与 Manager 基本一致
实战一下
基础用法
一般情况下 Specification 是检索条件,通过 append 追加条件,追加条件一般为与关系
第一个参数是字段,第二个参数是具体的值,值要和 Entity 的属性保持一致,例如 createdAt 比对的值就应该是 LocalDateTime 类型
这个方案对枚举值很友好,原则上来将,我们全部的状态、类型类的字段都应该用枚举值来管理,枚举值的好处是在 Vo 中,可以自动翻译为 code、message 的形式
Specification query = new BaseSqlQuery()
.append("status", CommonConstant.COMMON_VALID)
.append("auditStatus", AuditStatusEnum.APPROVED)
.append("position_In", positionEnumList);
List<SysUserEntity> userEntityList = userManager.findAll(query);
Or 操作
举个典型的场景,要根据关键字搜索用户,与姓名和手机号都模糊匹配
下面是要根据内容或者标签来搜索题目,那么下面的 sql 为and (content like '%?%' or labels like '%')
Specification<QuestionEntity> contentQuery = new BaseSqlQuery<QuestionEntity>()
.append("content_Like", searchWord);
Specification<QuestionEntity> labelsQuery = new BaseSqlQuery<QuestionEntity>()
.append("labels_Like", searchWord);
Specification<QuestionEntity> allQuery = contentQuery.or(labelsQuery);
query = query.and(allQuery);
2023 年 11 月,其实宇鹏很早在做项目时候,遇到了复杂的查询,就咨询过 TerryQi,我们致力于找到一个优雅的方法,实现优雅的嵌套多条件查询,那么这个目标没有达成,哪位有时间可以解决该问题,可以 call TerryQi,有奖励哦~
课题描述:我们希望达到的效果是 希望通过优雅的.or .and操作,实现类似于下面的复杂条件
A and ( B or ( C and D or (E or F)))
客观来说,失败了,由于上述的 or 操作并不优雅,所以在 3.1.3 版本中,对于我们常用的 ( A or B or C) 类单层的 Or 操作,BaseSqlQuery 提供了 or 操作符,满足这个需求,请注意:目前只支持单层的 or 操作,也就是不能嵌套
例子
BaseSqlQuery query = new BaseSqlQuery().append("status", CommonConst.COMMON_VALID);
query.or(new BaseSqlQuery().append("name", "大连").append("cityCode", "106012"));
List<SysProvinceCityEntity> entityList = provinceCityManager.findAll(query);
其含义如下,请注意,or 的含义是 其内部的条件是 or 的
where status = '1' and ( name = '大连' or cityCode = '106012')
Find_In_Set
很多情况下,我们会将多个 id 用逗号分割存为 xxx_ids 字段(varchar 类型),此时如果查找包含 id 的记录,一般用 MySql 的 find_in_set 方法
在 3.0.7 版本中,提供了_FindInSet方法,懂得自然懂
List<SysNationCodeEntity> entityList = nationCodeManager
.findAll(new BaseSqlQuery().append("code_FindInSet", "11"));
搜索数据范围
所谓 DataScope 是查询数据的范围,在 3.1.7 版本之前,无论 find、query、smartCount 等,默认都是查询没有被软删除的数据,即 deleted_flag='0'的数据,但是一些情况下,是需要查询被删除数据和全量数据的,这个情况下,就需要设置 dataScope,设置方法为
- 获取未软删除的数据
设置 dataScope==DataScopeEnum.NOT_DELETE,请注意不设置默认也是获取未软删除的数据,对应 sql 语句为deleted_flag=0
在 3.1.8 中,针对 findById 方法,也增加了 DataScope 字段,用于查询软删除字段
Specification query = new BaseSqlQuery().setDataScope(DataScopeEnum.NOT_DELETE);
- 获取被软删除的数据
设置 dataScope==DataScopeEnum.IS_DELETED,,对应 sql 语句为deleted_flag=1
Specification query = new BaseSqlQuery().setDataScope(DataScopeEnum.IS_DELETED);
- 获取全部的数据=未软删除数据+软删除数据
设置 dataScope==DataScopeEnum.ALL,,对应 sql 语句为deleted_flag between '0' and '1'
Specification query = new BaseSqlQuery().setDataScope(DataScopeEnum.ALL);
!!!请注意,dataScope 3.1.15 前只能用于 BaseSqlQuery,在 3.1.16 版本后, SmartQuery 也可以使用 dataScope。 但是请注意,默认是获取未软删除的数据,如果要获取软删除数据,则需要手动设置 dataScope 为 DataScopeEnum.IS_DELETED,或者需要获取全部数据,手动设置为 DataScopeEnum.ALL
Manager 用法
请注意,我们的建议是
Controller(->Service)->Manager->Repostory
具体详见JPA 通用,那么对于 Manager,通用方法如下:
| 方法名 | 说明 | 备注 |
|---|---|---|
| findOne | 获取一条数据 | 根据条件获取 1 条数据,要求只能映射到 1 条数据 |
| findById | 获取一条数据 | 根据 id 获取数据 |
| findAll | 获取列表/分页数据 | 送 Pageable 则获取分页数据 |
| query | 获取列表 | 同 findAll |
| get | 根据 id 获取数据 | |
| count | 统计数据 | 获取 count 数据 |
| save | 保存数据 | |
| saveAll | 批量保存 | |
| delete | 删除数据 | |
| deleteAll | 批量删除 | 这个批量删除是伪批量删除,本质还是串行模式删除 |
| setStatus | 设置状态 | |
| setSort | 设置排序 | |
| deleteBatch | 批量删除 | 3.0.6 版本新增批量删除,如果删除数据量特别大,可以使使用该方法,支持软删除和硬删除 |
| findFirstOne | 获取一条数据 | 3.0.1 版本新增获取一条数据,本质还是分页 |
锁机制
JPA 已经提供了良好的锁机制,主要有乐观锁、悲观锁两种,当然我们也可以在 redis 中造锁,但是目前来看大部分业务通过框架和数据库即可解决锁问题
下面描述的乐观锁和悲观锁都是 JPA 的锁机制
乐观锁
我们的基础数据模型规范中,全部库表都要有 version 字段,就是用于支持 JPA 的锁机制的 数据库规范
/**
* 版本号
*/
@Version
@Column(name = "version")
protected Integer version;
如果你的库表需要加锁,那么直接在 Entity 上增加上面描述即可。
请注意,乐观锁的确会保障数据不会被污染,如果遇到冲突,则接口直接报错抛出异常,在我的理解里,这个方案是不好的,影响了业务。目前没有理解到哪些业务用乐观锁合适,一般的钱包、积分类业务都应该使用悲观锁。
悲观锁
在碧桂园系统中,乐观锁出现问题,场景是:
- 用户的积分和活跃时间都记录到了 user 表中
- 用户参与游戏扣减积分
- 写了个拦截器,如果用户调用接口,修改用户的活跃时间(异步方式)
此时特别容易造成冲突,即用户可能同时修改积分和活跃时间
那么原来就是在 UserEntity 上加了@Version 的乐观锁,目测不行,转而使用悲观锁
- repository,增加锁,当然也可以写 SQL 里面带 for update
@Lock(LockModeType.PESSIMISTIC_WRITE)
public SysUserEntity findByUserId(Integer userId);
- manager,最好再包一层,修改用户积分时,套一个事务,然后执行下面方法获取用户信息,进行积分扣减即可
/**
* 带锁查找用户
* @return
*/
public SysUserEntity findByUserIdWithLock(Integer userId){
SysUserEntity userEntity = repository.findByUserId(userId);
return userEntity;
}
请注意,使用悲观锁要慎重,原则上只允许根据主键查询上锁,否则锁的面积太大
分组查询
以往我们的 BaseSqlQuery 中有 append 增加条件和 order 设置排序,那么是没有分组能力的,在 3.0.6 版本中,增加了 groupBy 字句,用于进行分组查询。 那么能够设想到的场景是:如果一个商品有多个分类,分类是由字典值管理的,那么想要获取数据库中所有的分类有哪些,此时可以用到 groupBy 字句
Specification query = new BaseSqlQuery().groupBy("status");
List<SysNationCodeEntity> entityList = nationCodeManager.findAll(query);
log.info("entityList:{}", JSON.toJSONString(entityList));
Assert.assertTrue(true);
上面语句的场景是有一个民族表,想要看到民族表中的 status 有哪些值,翻译成的 sql 语句就是下面,当然你也可以子在 repository 中自定义查询,或者用 distinct 的语法来编写,也都是可以的
SELECT
sysnationc0_.nation_code_id AS nation_c1_0_,
sysnationc0_.created_at AS created_2_0_,
sysnationc0_.created_by AS created_3_0_,
sysnationc0_.deleted_at AS deleted_4_0_,
sysnationc0_.deleted_by AS deleted_5_0_,
sysnationc0_.deleted_flag AS deleted_6_0_,
sysnationc0_.note AS note7_0_,
sysnationc0_.sort AS sort8_0_,
sysnationc0_.STATUS AS status9_0_,
sysnationc0_.updated_at AS updated10_0_,
sysnationc0_.updated_by AS updated11_0_,
sysnationc0_.CODE AS code12_0_,
sysnationc0_.NAME AS name13_0_
FROM
sys_nation_code sysnationc0_
WHERE
1 = 1
GROUP BY
sysnationc0_.STATUS
批量删除
以往,我们的 Manager 和 Repository 中也有 deleteAll 的方法,但是 deleteAll 本质是循环 delete 方法,效率会低一些(当然,我们一般情况下也没有大批量的删除,所以在大多数场景下不存在效率问题)。
在研究 JPA 自定义语句能力时,搂草打兔子,实现了 deleteBatch 方法,主要也是完善框架,如果你的项目中有大批量删除的业务场景,可以体验一下
List<Integer> idList = new ArrayList<>();
idList.add(1);
idList.add(2);
idList.add(3);
nationCodeManager.deleteBatch(idList);
其中 deleteBatch 还给了一个 force 参数,Boolean 类型,代表是否应删除,默认是软删除,硬删除将从数据库中删除
public void deleteBatch(List idList, Boolean force) {
this.getRepository().deleteBatch(idList, force);
}
字段为 json
在实际项目中,库表中部分字段需要使用 json 来实施,例如在烟台城发项目中,需要存储需求方的 json,那么需要
- 引入 json 处理包
pom.xml 加入依赖,下个版本计划这个依赖加到框架中
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-52</artifactId>
<version>2.4.3</version>
</dependency>
- 编写你映射 json 的数据结构
package com.qrqy.chengfa.data.demander.group;
import io.swagger.annotations.ApiModelProperty;
import io.swagger.annotations.ApiOperation;
import lombok.Data;
import java.io.Serializable;
/**
* @author TerryQi
* @since 2022/8/12 13:56
*/
@Data
public class DemandersJsonDo implements Serializable {
/**需求方id,即幼儿园id"**/
@ApiModelProperty(value = "需求方id ,即幼儿园id", example = "")
private Integer demanderId;
/**需求方名称,即幼儿园名称"**/
@ApiModelProperty(value = "需求方名称,即幼儿园名称", example = "")
private String name;
/**联系人姓名"**/
@ApiModelProperty(value = "联系人姓名", example = "")
private String contactName;
/**联系人电话"**/
@ApiModelProperty(value = "联系人电话", example = "")
private String contactPhoneNumber;
/**省"**/
@ApiModelProperty(value = "省", example = "")
private String province;
/**市"**/
@ApiModelProperty(value = "市", example = "")
private String city;
/**区"**/
@ApiModelProperty(value = "区", example = "")
private String area;
/**需求方地址"**/
@ApiModelProperty(value = "需求方地址", example = "")
private String address;
}
- Entity 中实施一下,demandersJson 这个字段就是 json 的字段
package com.qrqy.chengfa.dao.entity;
import com.fasterxml.jackson.databind.annotation.JsonDeserialize;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
import com.qrqy.chengfa.data.demander.group.DemandersJsonDo;
import com.qrqy.chengfa.enums.purchase.task.PurchaseTaskStatusEnum;
import com.qrqy.developer.common.entity.CommonEntity;
import lombok.Data;
import lombok.EqualsAndHashCode;
import org.hibernate.annotations.Type;
import org.springframework.data.jpa.domain.support.AuditingEntityListener;
import javax.persistence.*;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;
/**
* @author : jCoder
* @date : 2022-08-12 11:16
*/
@Data
@EqualsAndHashCode(callSuper = true)
@Entity
@Table(name = "cf_purchase_sub_task")
@EntityListeners(AuditingEntityListener.class)
public class CfPurchaseSubTaskEntity extends CommonEntity implements Serializable {
private static final long serialVersionUID = 7406912254492452506L;
/**
* PK
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "purchase_sub_task_id")
private Integer purchaseSubTaskId;
/**
* 采购任务id
*/
@Column(name = "purchase_task_id")
private Integer purchaseTaskId;
/**
* 子任务名称
*/
@Column(name = "sub_task_name")
private String subTaskName;
@Column(name = "batch_no")
private String batchNo;
/**
* 需求方分组id
*/
@Column(name = "demander_group_id")
private Integer demanderGroupId;
/**
* 需求方ids,多个id用逗号分割
*/
@Column(name = "demander_ids")
private String demanderIds;
@Column(name = "demander_group_name")
private String demanderGroupName;
@Type(type = "json")
@Column(name = "demanders_json",columnDefinition = "json")
private List<DemandersJsonDo> demandersJson;
/**
* 报名开始时间
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@Column(name = "sign_up_start_at")
private LocalDateTime signUpStartAt;
/**
* 报名结束时间
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@Column(name = "sign_up_end_at")
private LocalDateTime signUpEndAt;
/**
* 任务状态,NOT_PUBLISH:未发布;HAS_PUBLISHED:已发布;FINISHED:已结束
*/
@Column(name = "task_status")
@Enumerated(EnumType.STRING)
private PurchaseTaskStatusEnum taskStatus = PurchaseTaskStatusEnum.NOT_PUBLISH;
/**
* 需要商品总数量
*/
@Column(name = "total_product_num")
private Integer totalProductNum;
/**
* 需要商品总价格
*/
@Column(name = "total_price")
private BigDecimal totalPrice;
}
JPA 审计
JPA 审计是自动向库表中添加 createdBy、createdAt、updatedBy、updatedAt 等信息,目前 JPA 审计功能放在框架中。
背景
以往,根据我们的数据库模型定义,用户 id 都保存为 Integer 类型,Entity 直接集成 CommunitEntity 即可。在 2022 年 9 月实施阜新招商项目时,使用合作方团队的 OA 进行人员和组织架构的管理,合作方团队用户 id、组织架构 id 都设置为 String 类型,此时与我们的数据模型定义不一致,为了解决该问题,升级框架到 3.0.5 版本。
Community2Entity
Community2Entity 在原有 CommunityEntity 的基础上增加了泛型。
@Data
@MappedSuperclass
public abstract class Common2Entity<ID> {
/**
* 状态,0:失效,1:有效,主要考虑兼容性
*/
@Column(name = "status")
protected String status = "1";
/**
* 备注
*/
@Column(name = "note")
protected String note;
/**
* 排序
*/
@Column(name = "sort")
protected Integer sort = 99;
/**
* 删除标记,0:未删除;1:已删除
*/
@Column(name = "deleted_flag")
protected String deletedFlag = "0";
/**
* 创建用户
*/
@CreatedBy
@Column(name = "created_by")
protected ID createdBy;
/**
* 创建时间戳
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@CreatedDate
@Column(name = "created_at")
protected LocalDateTime createdAt;
/**
* 更新用户
*/
@LastModifiedBy
@Column(name = "updated_by")
protected ID updatedBy;
/**
* 更新时间戳
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@LastModifiedDate
@Column(name = "updated_at")
protected LocalDateTime updatedAt;
/**
* 删除用户
*/
@Column(name = "deleted_by")
protected ID deletedBy;
/**
* 删除时间戳
*/
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
@JsonSerialize(using = LocalDateTimeSerializer.class)
@Column(name = "deleted_at")
protected LocalDateTime deletedAt;
}
那么,在使用时,Entity 可以定义主键的类型。
@Data
@EqualsAndHashCode(callSuper = true)
@Entity
@Table(name = "sys_nation_code")
@EntityListeners(AuditingEntityListener.class)
public class SysNationCodeEntity extends Common2Entity<Integer> implements Serializable {
private static final long serialVersionUID = 432550535284913460L;
/**
* PK
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "nation_code_id")
private Integer nationCodeId;
/**
* 民族名称
*/
@Column(name = "name")
private String name;
/**
* 民族编号
*/
@Column(name = "code")
private String code;
/**
* 状态,1:有效;0:无效
*/
@Column(name = "status")
private String status;
}
UserLoginDo 有需要调整
其中,在各个项目中的 UserLoginDo 也应该相应调整一下
@Data
public class UserLoginDo<ID> implements IBaseUserDetails<ID>, Serializable {
private static final long serialVersionUID = 5900016730059591925L;
/**
* 主键
*/
private ID userId;
/**
* 预留id,一般为hash值
*/
private String uuid;
/**
* 昵称
*/
private String nickName;
/**
* 真实名称
*/
private String realName;
/**
* 头像图片
*/
private String avatar;
/**
* 手机号
*/
private String phoneNumber;
/**
* 用户签名
*/
private String sign;
/**
* 用户性别;UNKNOWN:保密;MALE:男性;FEMALE:女性;
*/
private String gender;
/**
* 国家
*/
private String country;
/**
* 省份
*/
private String province;
/**
* 城市
*/
private String city;
/**
* 地址
*/
private String address;
/**
* 区
*/
private String area;
/**
* 生日
*/
private LocalDate birthday;
/**
* 语言
*/
private String language;
/**
* 用户状态
*/
private String status;
/**
* token信息,带Bearer头
*/
private String token;
/**
* token信息,带Bearer头
*/
private List<RoleDo> roleList;
/**
* 授权信息
*/
private Collection<? extends GrantedAuthority> authorities;
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
if (roleList==null){
return new ArrayList<>();
}
return roleList.stream().map(role -> new SimpleGrantedAuthority("ROLE_" + role.getRoleId())).collect(Collectors.toList());
}
@Override
public String getPassword() {
return null;
}
@Override
public String getUsername() {
return this.realName;
}
@Override
public boolean isAccountNonExpired() {
return true;
}
@Override
public boolean isAccountNonLocked() {
return true;
}
@Override
public boolean isCredentialsNonExpired() {
return true;
}
@Override
public boolean isEnabled() {
return true;
}
}
日志审计代码
SpringSecurityAuditorAware.java 就是日志审计的代码,目前在框架中。
@Component
@Slf4j
public class SpringSecurityAuditorAware implements AuditorAware<Object> {
@Override
public Optional<Object> getCurrentAuditor() {
try {
Object principal = SecurityContextHolder.getContext().getAuthentication().getPrincipal();
Object userId;
if (principal instanceof IBaseUserDetails) {
userId = ((IBaseUserDetails<Object>) principal).getUserId();
} else {
userId = null;
}
return Optional.ofNullable(userId);
} catch (NullPointerException e) {
return Optional.empty();
}
}
}